9.4 KiB
Cat Bookmarker
This project was created in under a day in 2022 as a part of an assessment. It's a cat bookmarking web app! It consumes JSON representations of cat images accessible via the Cataas API, the links to which can be permanently stored in a bookmark database.
Screenshots

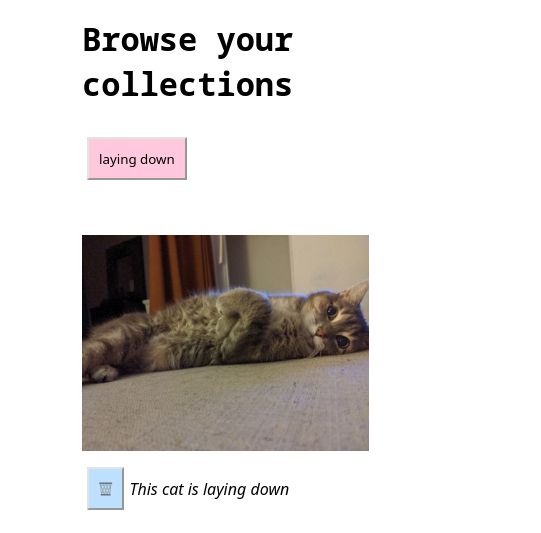
Running the server
To run the server, you'll need:
- Elixir, which depends on Erlang. Detailed instructions on how to install Elixir and Erlang can be found on the Elixir website. In most cases, installing Elixir will get you a copy of Erlang as well.
- Node.js. If you've been blessed to have never needed to download Node on your device, you can end that streak now by visiting the Node.js download page
- PostgreSQL, which you'll need running. You can find information on how to install it on the PostgreSQL download page as well.
Aside: Setting up Postgres
By default this project assumes your PostgreSQL install has a user with the name "postgres" whose password is "postgres". Is that not the case? Either:
- Change the configuration to use the right credentials. Open
./config/dev.exsand find and edit:config :bookmarker, Bookmarker.Repo, username: "<YOUR USERNAME>", password: "<YOUR PASSWORD>", - Change your password, say, to "postgres". If you're on Linux, this would look something like:
# Run the postgresql console as the postgres user $ sudo -u postgres psql # reset the password postgres=# \password <username> Enter new password for user "<username>": Enter it again: postgres=# \q
Finally, set up and run the server
$ cd bookmarker
$ mix deps.get # Install Elixir dependencies
$ mix ecto.setup # Set up the database
$ cd assets
$ npm install # Install Node dependencies
$ cd ..
$ mix phx.server # Run the server
You can then navigate to localhost:4000 to find the front end of the application.
Details
The form submits four pieces of data:
category: The name of the category the bookmark will be stored undernotes: Any extra details, stored as a single stringremote_id: The ID of the resource accessible via Cataas' APIcreator: A pseudo-anonymous integer ID representing the actor bookmarking the image
The first two are literally HTML input elements. The third is selected randomly by repeatedly pressing the "Show New Cat" button. The third is represented by a route both in Phoenix and using React Router.
The tech stack for this project is as follows:
- Elixir, the back-end programming language
- Phoenix, which is the Ruby On Rails of Elixir
- PostgreSQL as the database
- React for the front-end
The front-end of this project is a single-page app that uses React Router to navigate between the two "pages."
All of the API endpoints are under the /api/v1/ route, and since this project only really does bookmarking, all of them ended up being under /api/v1/bookmark. The three required routes are as follows, followed by the other routes I added for convenience:
- POST /api/v1/bookmark - Accepts a JSON payload with keys
remote_id,notes, andcategoryand stores it in the database. - GET /api/v1/bookmark/single/:id - Returns a single bookmark with the given ID. If The user doesn't have any bookmarks with that ID, the server returns an error with a 404 status code.
- GET /api/v1/bookmark - Returns all of the user's bookmarks.
- DELETE /api/v1/bookmark/:id - Deletes the bookmark
- GET /api/v1/bookmark/category/:category - Returns all bookmarks in
:category - GET /api/v1/bookmark/categories - Returns an array of strings, each representing the name of a category that has at least one bookmark
Rudimentary authentication
Accounts are generated in the same way some conferencing software gives users semi-private meeting rooms represented by a random string of words. That way, anyone with the link can access it, but it's not particularly easy to find a given room without knowing the string of words in advance.
I didn't feel like putting together a large dictionary of words, so I just used JavaScript's pseudo-random number generator to generate a probably-unique user ID (or at least, there's only a one in a million chance of a clash).
The user's page is accessible by accessing the /u/:id route, where :id is the user's ID number
When making calls to the API, the client passes an Authorization header to their request including their ID, such as Authorization: Basic 1234.... If this header is omitted or malformed, the server returns a 401 status code. Not production-grade by any means, but not bad for a cat bookmarking app.
Reading the code
Phoenix automatically generates a lot of stuff that isn't really relevant to this project, so there's really only a few places you need to focus on.
- bookmarker/
- lib/ - All of the back-end code
- bookmarker/bookmarker.ex - the description of the database entries
- bookmarker_web/
- router.ex - The routes for the API and UI
- controllers/app_controller.ex - The functions that control what happens when a client accesses a route in the UI
- controllers/api_controller.ex - The functions that control what happens when a client accesses a route in the API
- assets/ - All of the front-end code
- js/app.js - The main JavaScript file containing the root React component and routing information
- js/home.js - The home page component
- js/bookmarks.js - The component for the page used to bookmark cats and review bookmarks by category
- css/app.css - All of the application's styles
- lib/ - All of the back-end code
Possible improvements
Security
In some places, API requests to resources not owned by the user will return a message along the lines of "you cannot access other people's resources." It would probably be a better practice to simply return a 404 status code and tell the client the resource cannot be found in these places, as implying that the client has stumbled upon another user's resources could potentially be compromising.
The decision to use integers to represent users was arbitrary. I very well could have used alpha-numeric strings or, even better, a series of four or five random words. With a large enough dictionary, using a string of words would improve security and memorability.
That being said, the biggest issue with using Authorization headers is that if the connection isn't being made over HTTPS, then confidential information is being traded in plain-text. Either additional steps would have to be taken to prevent snooping or an alternative, more rigorous method of user-management would have to be put into effect to ensure the security of everyone's cat bookmarks.
Efficiency
The front-end being a single-page app presents some issues. Particularly, you
can't directly access localhost:4000/u/:id without confusing Phoenix, because
/u/:id isn't a real route. To get around this, I made the hack-ish decision
to redirect that route to /?u=:id and then have the Home component listen for
query parameters before redirecting the client again to the page they're looking
for. While this works, it's kind of gross and inefficient. There isn't really
any need for this project to be a single-page app. It'd perhaps do even better
with a separate page for the two routes.
In a production environment, more thought would need to go into how many connections to the database ought to be pooled to prevent a bottleneck.
React is a fairly big blob of JavaScript to use in such a simple project. I could probably do away with it entirely if I was willing to put up with vanilla JS, or use a lightweight alternative like Preact. Alternatively, I could have also chosen to do more on the server-side instead of leaving everything short of the API up to the client.
Functional improvements
Some functions that control what happens when a client navigates to a route do dangerous actions, such as ignoring potential errors that seem unlikely instead of handling them. This code should be replaced with better error-handling mechanisms on the off-chance that they do actually come up.
There should be more custom error pages implemented, particularly in the case of the user-facing interface. The user should never be presented with a complete stack trace, for example.
Deployment considerations
Elixir is well known for being able to accomplish quite a bit with limited resources. Many Phoenix projects run just as well on a Raspberry PI as they do on any other device. However, as someone who's tried to self-host services built using the Phoenix framework, I find that managing the dependencies can be a bit of a nightmare. That's one major advantage that the Express/Node pairing has over Phoenix and Elixir: it's everywhere. You'd be hard pressed to find a developer who doesn't have Node installed on their computer.
In cases like this, I like to look for containerized versions of the services, usually through Docker. It's much easier to manage that way.